콘텐츠
최근 네이버 서치어드바이저에서 드디어 내 블로그 글을 수집하였다.
글이 50 개가 가까워 짐에도 7개의 게시글 만이 네이버에 노출이 되고 있던 상황에서 네이버 고객센터 문의 를 하고 나니 한꺼번에 380 개가 넘는 게시 글이 수집 되었다.
문제는, 이렇게 수집한 글 내용을 확인해 보니까 wp-admin 과 같은 굳이 가져가지 않았어도 될 내용도 수집이 되었단 것이다. 이건 아무래도 모든 게시글을 수집하게 만든 Robots.txt 수정이 원인이 된 것 같다.
그래서 Robots.txt 를 수정하여 이를 해결해보고자 한다.
Robots.txt 란?
robots.txt는 웹 크롤러 및 기타 웹 로봇들에게 어느 부분을 처리하거나 스캔하지 않아야 하는지를 알리기 위한 웹사이트에서 사용되는 표준이다.
본 파일은 웹사이트의 루트에 위치하며, 웹 크롤러에게 주어진 제한 사항들을 알려준다. 예시로, 웹사이트 주소가 https://example.com일 경우, robots.txt 파일은 https://example.com/robots.txt 에 위치하게 된다.
내 블로그도 https://mntkim.com/robots.txt 에 접속 할 경우 확인이 가능하다.

Robots.txt 내용 분석
Robots.txt 의 내용에서 User-agent 란 웹크롤러 (Bot)의 이름이 들어간다. 구글이라면 Googlebot, Bing은 Bingbot 등이다. *는 모든 Agent에 적용될 규칙이다.
내 블로그 같은 경우는 크롤러에 그냥 모든 URL을 수집할 수 있게 되는 것이다.
여기서 특정 URL을 접근하지 못하게 하려면 추가적으로 Disallow 를 추가하면 된다.
WordPress 에서 Robots.txt 수정하기
내 블로그는 Yoast SEO 가 적용 되어 있다.
그럼 Robots.txt 를 Yoast SEO 에서 변경 할 수 있다.
1. 워드프레스 관리자 설정 접속
2. 좌측 메뉴 Yoast SEO > Tools 선택

3. File editor 선택
여기서 robots.txt 를 수정할 수 있다.
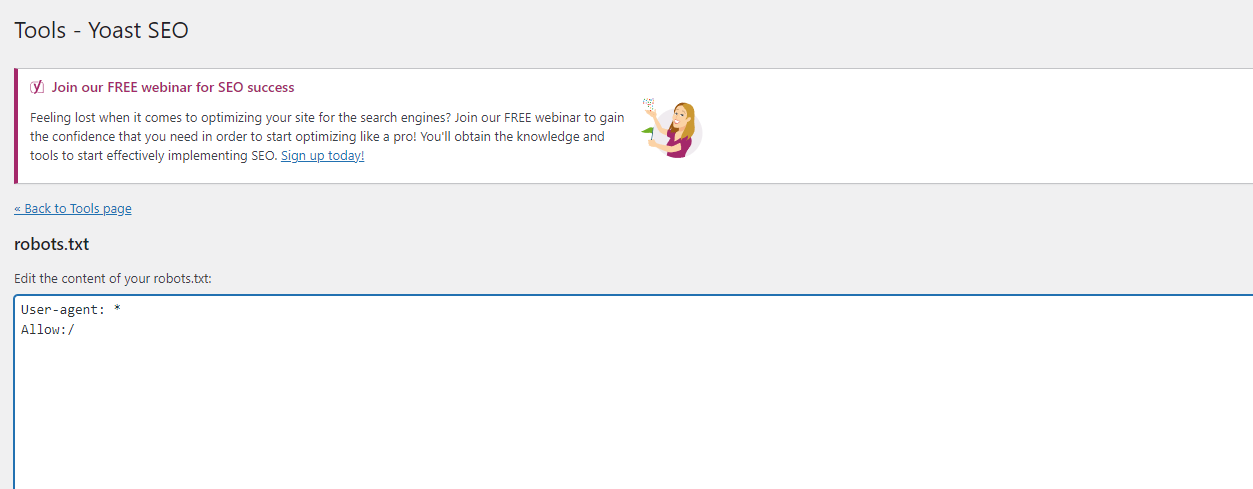
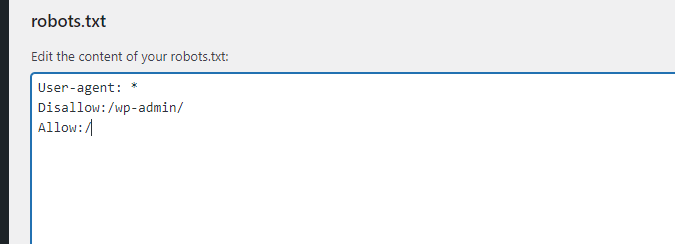
Robots.txt 에서 WordPress 관리자 URL 수집 막기
다음과 같이 Disallow 를 파일에 추가해주면 된다.
네이버 서치어드바이저 에서 확인하기
해당 Robots.txt 를 적용하고 나선 서치어드바이저 에서 확인 할 수 있다.
1. 네이버 서치어드바이저 접속
2. 왼쪽 메뉴 검증 > robots.txt 접속
3. 수집요청 버튼으로 robots.txt 정보 끌고오기
 제외하기")
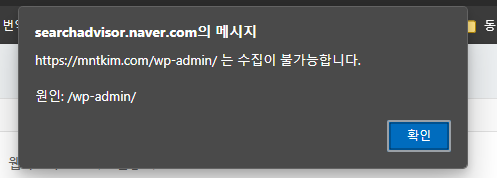
4. robots.txt 검증에 해당 URL이 끌고 와 지는지 검색하기

포스팅 요약
1. 문제 상황 파악
- 초기 상황: 글 50개 중 7개만 네이버에 노출.
- 문제 발견: 네이버 서치어드바이저가 블로그 포스팅 수집 시 “수집 보류” 상태 지속.
2. 초기 점검 사항
- 주소 형식 변경 여부
- 사이트맵 및 RSS 재등록 여부
- 서치어드바이저 간단체크 진행
- robots.txt 파일 검증
3. Robots.txt 파일 소개
- 정의: 웹 크롤러에게 어떤 부분을 스캔하거나 처리하지 않아야 하는지 지시하는 표준 파일.
- 위치: 웹사이트 루트 디렉토리 (예: https://example.com/robots.txt)
4. Robots.txt 파일 수정 방법 (워드프레스 기준)
- 워드프레스 관리자 페이지 접속
- 왼쪽 메뉴에서 Yoast SEO > Tools 선택
- File editor 옵션 클릭하여 robots.txt 파일 직접 수정
5. WordPress 관리자 URL 수집 방지 방법
- robots.txt 파일에 “Disallow” 규칙 추가하여 특정 URL 접근 제한 설정 가능.
6. 네이버 서치어드바이저에서 수정 내용 확인 방법
- 네이버 서치어드바이저 로그인
- 왼쪽 메뉴에서 “검증 > robots.txt” 접속
- “수집요청” 버튼 클릭하여 최신 robots.txt 정보 가져오기
- robots.txt 검증에서 해당 URL 정보 확인
주의 사항: 불필요한 내용이 수집 되지 않도록 robots.txt 파일을 정확하게 수정하고 검증할 것을 권장한다
Disallow 와 Noindex Page 간의 차이
페이지의 색인을 막는 방법에는 Disallow 외에도 Noindex 지정으로 Page 의 접근을 막을 수도 있다. Noindex 는 Robots.txt 에 적용하는 방법은 아니고 검색되지 않고자 하는 특정 페이지 HTML 에 메타 태그로 지정하여 사용된다.
둘 다 검색 엔진의 노출을 막기 위해 크롤링, 색인화를 방지 하는 것이지만, Disallow 는 특정 페이지의 ‘크롤링’ 을 막는 것이고 Noindex 는 ‘색인화’ 를 막는 것.
크롤링은 검색 엔진 로봇(크롤러) 가 인터넷을 탐색해 웹 페이지를 찾아 그 내용을 읽는 것이고 색인화는 이후 검색 엔진의 DB에 저장되는 과정이다.
즉, Disallow 를 사용하면 크롤러가 해당 페이지를 접근하지 않게 되지만, 가령 수동으로 색인 하는 것을 막을 순 없게 된다.
Noindex 는 색인화가 되지 않아 검색엔진엔 노출되지 않아도 지속적으로 크롤러가 접근할 수 있다.
그래서 내 생각엔 둘 다 되지 않기 원한다면 두 가지 방법 모두 사용해야 할 것.


