콘텐츠
Puppeteer

Puppeteer 는 Google 이 만든 웹 브라우저 기반 자동화 Node.js 라이브러리 입니다. Node.js 의 모듈은 코드를 구성하는 기본 단위(함수, 클래스, 객체, 기타코드 등으로 구성)라면 라이브러리는 특정 작업을 수행하기 위해 재사용 가능한 코드의 모음이죠.
Puppeteer 는 구 중에서도 구글의 Chromium 혹은 Chrome 환경에서 동작하며 지정한 웹 사이트 관련 작업을 자동화 해주는 목적을 지녔습니다. 기본적으로 소개 드릴 작업은 Google 사이트에 접속해 메인 화면을 촬영해 png 파일로 저장하는 것, 페이지 내의 정보를 추출 하는 등의 동작이 가능 합니다.
Puppeteer 사용 방법
먼저 다음 게시글을 참고해서 Node.js 프로젝트를 만들어 주세요.
Visual Studio Code 로 Node.js 개발 시작
라이브러리 설치
Puppeteer 는 npm install 을 통해 Node.js 기반 프로젝트에 설치가 가능 합니다.
npm install puppeteerPuppeteer 기본 예제
다음 코드는 Puppeteer 를 이용해 Google 에 접속하고 해당 화면의 스크린샷을 찍고 파일로 저장하는 예제 코드 입니다. 프로젝트 내에 원하는 파일 명의 js 파일을 만들고 아래 코드를 작성하세요.
그 후 ‘Node 파일명.js’ 를 터미널에 입력하면 google.com 에 접속 한 후 해당 화면을 google.png 파일로 스크린샷을 찍고 저장 합니다.\
(1) 코드 작성
const puppeteer = require('puppeteer');
async function run() {
// Puppeteer 인스턴스를 실행
const browser = await puppeteer.launch();
const page = await browser.newPage();
// Google 웹 페이지를 열기
await page.goto('https://google.com');
// 스크린샷을 찍고 파일로 저장
await page.screenshot({path: 'google.png'});
// 브라우저 종료
await browser.close();
}
run();- Puppeteer 도 이전 HTTP 통신 모듈들처럼 비동기 작업을 위한 promise 객체 기반으로 되어 있습니다.
- 해당 동작은 머리 없는(Headless)모드로 수행 됩니다. 이는 GUI 없이(눈에 안 보이는 상태에서) 작업이 수행된다는 의미 입니다.
(2) 작성 Node.js 파일 실행
node index.js(3) 코드 정상 실행 시 google.png 파일이 생성 된다.
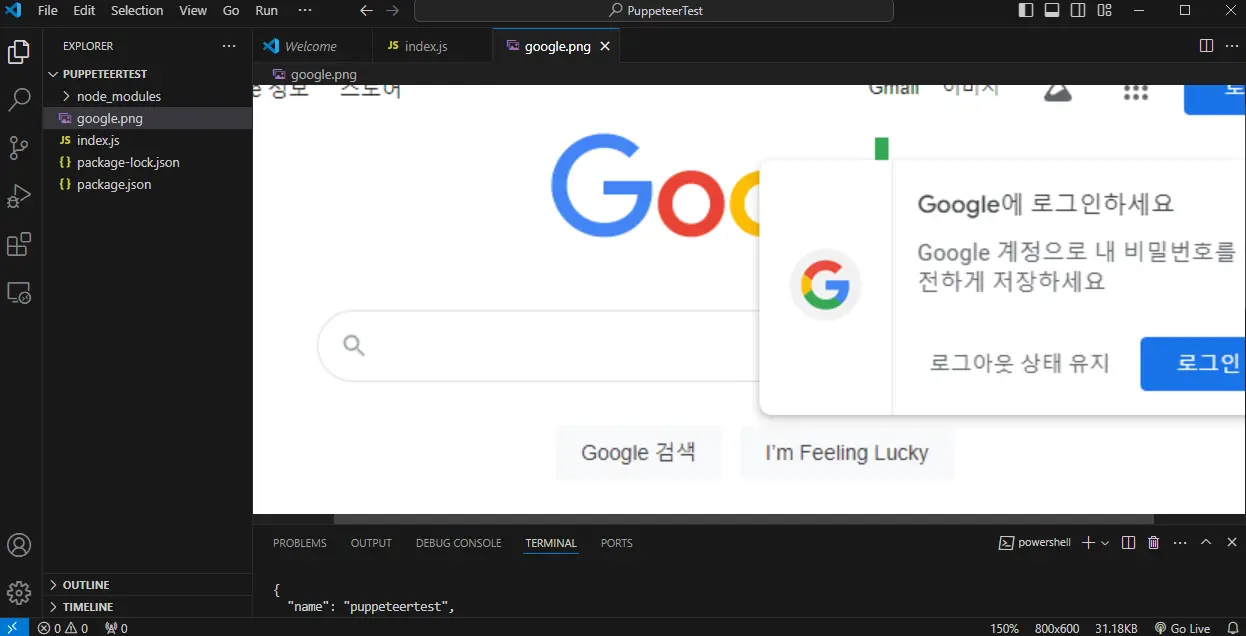
Puppeteer 로 페이지 내 정보 읽어오기
이번엔 좀 더 실질적으로 사용해 보기 위해 스크린샷을 찍는 것이 아닌 다른 메서드를 이용해서 페이지 내의 정보를 읽어 오겠습니다. 한번 제 블로그에 접속해서 위의 코드를 이용해 스크린샷이 저장 되는지 해보겠습니다.
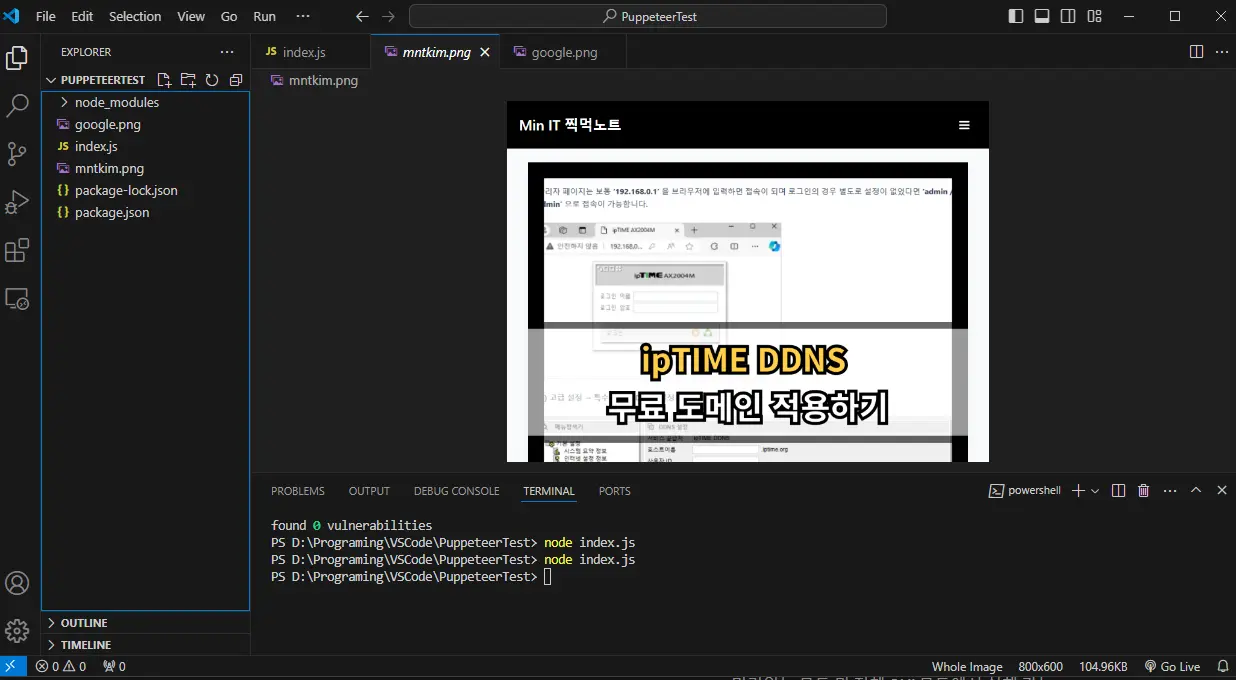
해보니 정상적으로 제 블로그에도 접근해 스크린샷이 찍히는 것이 확인 되었습니다. 이번엔 스크린샷을 찍어보지 말고 사이트 내의 정보를 가져와 보겠습니다. 이 때 사용하는 메서드는 .evaluate() 입니다.
.evaluate()
해당 메서드는 페이지 내의 정보를 읽어오는 메서드로 인자로 콜백 함수를 받아 함수 내에서 document 변수명으로 접근이 가능 합니다. 예를 들어 다음 코드를 page.goto 아래 작성해 document 변수 내의 title 을 이용해 페이지 내 제목을 읽어올 수 있습니다.
// 페이지 타이틀 추출
const pageTitle = await page.evaluate(() => {
return document.title;
});
// 결과 출력
console.log(`Page title: ${pageTitle}`);그럼 제 블로그 제목인 Min IT 찍먹노트 – IT, BLOG 가 출력 됩니다.
이를 통해 사용해 볼 수 있는 메서드 들은 공식 홈페이지 API 문서에서 확인 가능 합니다.
evaluate 에 담긴 document 객체는 저희가 평소 프론트엔드 에서 사용하던 자바스크립트의 document 객체처럼 page.goto 메서드를 통해 접속한 site 의 정보가 담기게 됩니다. 즉, Vanilla JS 를 사용하듯 querySelector, getElementById 등을 사용할 수 있습니다.
이를 응용해 제 사이트의 메인에 접속한 후 document 객체를 통해 페이지 내 모든 링크를 가져와 출력해 보니 정상적으로 링크들을 가져 옵니다. 아래 코드는 그대로 두고 접근 URL 만 바꾸면 다른 사이트에서도 동작이 가능 합니다.
const links = await page.evaluate(() => {
const anchors = Array.from(document.querySelectorAll('a'));
return anchors.map(anchor => anchor.href);
});
console.log(`Links: ${links.join(', ')}`);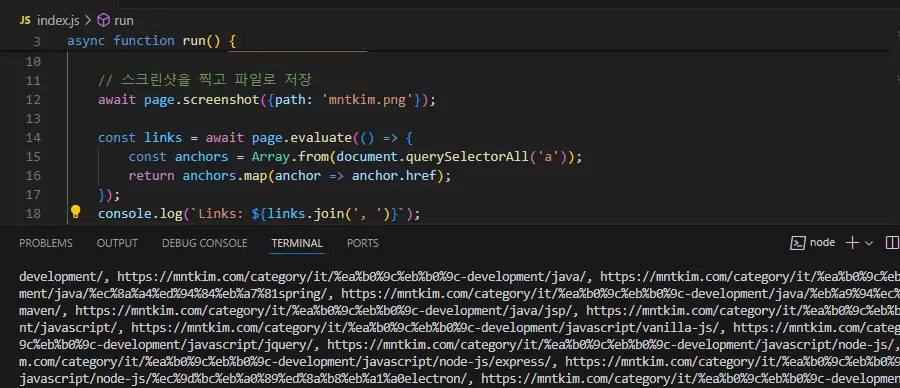
실행 과정 눈으로 직접 보기
위에서 이야기한 머리 없는(Headless)모드를 옵션으로 비활성화 하여 실제 동작 과정을 눈으로 볼 수도 있습니다. 이는 launch 메서드에 옵션 객체를 전달하면 되고 키는 headless 입니다.
const browser = await puppeteer.launch({ headless: false })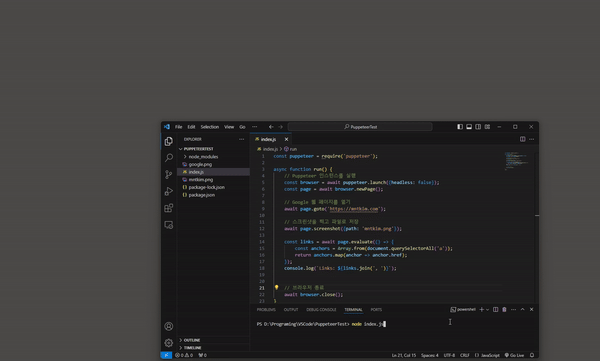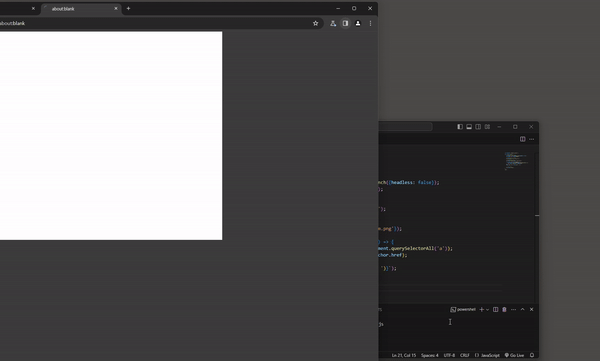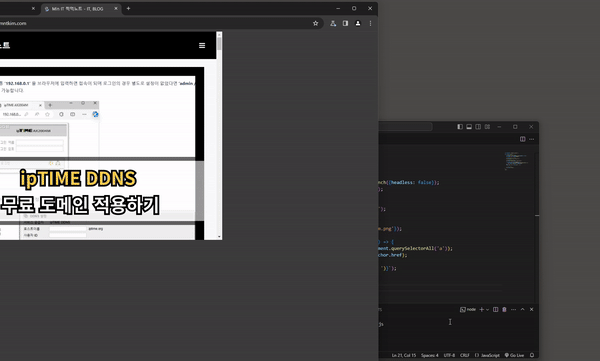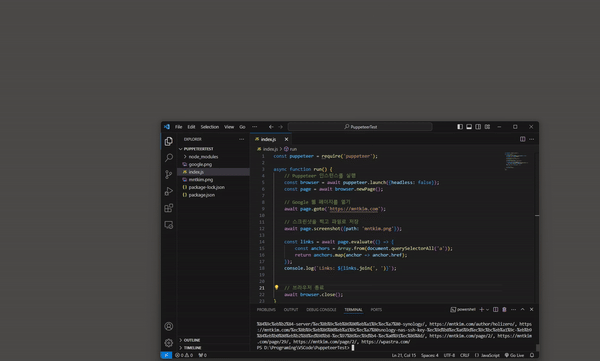



 서버 내 파일 생성, 삭제, 읽기, 쓰기")