콘텐츠
이전 포스팅을 통해 Hugging Face 에서 제공하는 Transformers 라이브러리를 설치 하였고 간단한 예시 코드를 실행해 보았다. 내가 이 라이브러리로 주로 하고 싶었던 작업은 문장 요약으로 메일/대화 등 텍스트의 문맥을 파악해 제목을 만들고 싶어 실행을 해보니 요약이 되긴 하지만 결과 퀄리티가 매우 낮았다.
그러다 Trasformers 는 개발자가 직접 자신이 원하는 형태로 AI 모델을 파인 튜닝(Fine-tuning)을 할 수 있다는 정보를 얻어 시도해 보았다.
파인 튜닝(Fine-tuning) 이란?
파인 튜닝은 영어 단어 Fine(미세한, 정밀한) 과 Tunning (조정, 조율)의 합성어로 말 그대로 이미 학습 된 AI 모델을 사용자가 도메인(Domain, 특정한 주제, 분야 또는 응용 영역)에 맞춰 추가 학습 시키는 과정을 이야기한다.
일반적으로 최신 AI 모델의 경우 일반적인 언어 패턴들을 학습하여 자연스러운 대화를 이미 이끌어내고 있지만 전문적으로 좀더 튜닝 할 수 있는 것이다.
예를 들어 내가 사용하는 AI 모델이 문장을 요약할 때 좀 더 IT 기업이나 혹은 내가 다니는 회사에 특화된 형태의 문장으로 요약, 정보를 생성하고 싶을 때 파인 튜닝을 통해 원하는 결과를 표시 하도록 학습 시키는 것이며 Transformers 는 이 파인 튜닝을 지원한다.
데이터셋(DataSet)
데이터셋은 말 그대로 데이터의 집합이다.
지금의 경우엔 머신러닝, 딥러닝 등 AI 모델을 훈련, 검증, 테스트 등을 위해 활용하려 데이터를 모아둔 것을 의미하며 만약 내가 영화 리뷰 관련 AI 특화 모델로 파인튜닝을 할 예정이라면 영화 관련 정보를 학습에 유리한 템플릿에 맞춰 정리한 것을 의미한다.
파인 튜닝 과정
이제 실제로 Python 을 이용해 파인 튜닝을 진행해 볼 것인데 이와 관련해서 Python 및 관련 라이브러리, 패키지가 설치 되었다는 가정 하에 글을 작성할 것이다.
만약, 아직 설치된 상태가 아니라면 다음 포스팅을 참고해서 먼저 사전 준비부터 한다.
Hugging Face Transformers 설치 방법: Python으로 NLP 시작하기
1. 데이터셋(DataSet) 로드 및 생성
학습 시킬 데이터 셋을 불러온다. 이 경우 Python 의 datasets 라이브러리를 사용 중 이라면 이미 준비 되어 있는 데이터 셋을 사용할 수 있다.
예를 들어 영화, TV 프로그램, 게임 등의 정보와 리뷰를 제공하는 온라인 데이터베이스인 imdb 의 영화 관련 데이터셋을 불러와 관련 데이터를 학습 시키려면 다음과 같이 가져올 수 있다.
from datasets import load_dataset
# IMDB 감성 분석 데이터셋 불러오기
dataset = load_dataset("imdb")
# 데이터셋 구조 확인
print(dataset)모듈에서 제공되는 데이터 외에 직접 데이터셋을 만들 수도 있다.
아래 코드는 메일 내용을 다음과 같은 제목으로 요약하기 위해 단순하게 데이터셋을 만들어본 예시 코드이다.
먼저 딕셔너리, 리스트가 조합이 된 변수 datas 를 만들고 Python 의 데이터 분석, 조작에 매우 유용하게 사용되는 pandas 라이브러리를 이용하여 데이터프레임(DataFrame, 행과 열을 지닌 데이터 구조)화 하였다.
pandas 를 사용하기 위해선 설치가 우선 되어야 하고 pip install pandas 명령어를 통해 설치할 수 있다.
import pandas as pd
datas = {
'content': [
"안녕하세요. 인사팀 김지영입니다. ‘25년 파이썬 교육 입과 안내 드립니다.",
"안녕하세요. 마케팅팀 김철수입니다. 다음 주 월요일에 있을 마케팅 전략 회의 자료를 공유드립니다."
],
'title': [
"‘25년 파이썬 교육 참석 요청",
"마케팅 전략 회의 자료 공유"
]
}
data = pd.DataFrame(datas)2. 사전 학습 된 모델 로드
파인 튜닝 할 AI 모델을 가져오는 과정이다.
이 모델에는 다양한 종류가 존재하는데 나는 그 중 에서도 문서 요약 특화 되어있고 한국어를 잘 인식한다는 gogamza/kobart-summarization 모델을 사용하였다.
모델을 로드하는 코드는 다음과 같다.
# 1. Hugging Face 라이브러리에서 필요한 모듈 불러오기
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
# 2. 사용할 KoBART 요약 모델의 이름 설정
model_name = "gogamza/kobart-summarization"
# 3. 해당 모델에 맞는 토크나이저 불러오기
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 4. 해당 모델 불러오기 (Seq2Seq 모델)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)3. 데이터셋 객체 생성 (데이터 전처리)
위에 만들었던 데이터 변수를 학습을 하기 위한 데이터로 변환하는 과정이다. 내가 하려는 작업은 이메일의 내용을 제목으로 요약하기 위한 데이터셋을 만들고자 하는 것으로 이를 위한 클래스를 만들었으며 이름을 EmailTitleDataset 으로 지었다.
from torch.utils.data import Dataset # PyTorch Dataset 불러오기
class EmailTitleDataset(Dataset):
def __init__(self, contents, titles, tokenizer, max_input_length=1024, max_output_length=50):
self.contents = contents
self.titles = titles
self.tokenizer = tokenizer
self.max_input_length = max_input_length
self.max_output_length = max_output_length
def __len__(self):
return len(self.contents)
def __getitem__(self, idx):
input_text = self.contents[idx]
target_text = self.titles[idx]
# 입력 텍스트 인코딩
input_encodings = self.tokenizer(
input_text,
truncation=True,
padding="max_length",
max_length=self.max_input_length,
return_tensors="pt"
)
# 타겟(제목) 텍스트 인코딩
target_encodings = self.tokenizer(
target_text,
truncation=True,
padding="max_length",
max_length=self.max_output_length,
return_tensors="pt"
)
# 각 텐서에서 배치 차원 제거
input_encodings = {k: v.squeeze() for k, v in input_encodings.items()}
target_encodings = {k: v.squeeze() for k, v in target_encodings.items()}
# 모델 학습 시 loss 계산을 위해 labels 추가
input_encodings["labels"] = target_encodings["input_ids"]
return input_encodings* 위의 코드는 PyTorch 의 Dataset 클래스를 상속 받아 만들어졌다.
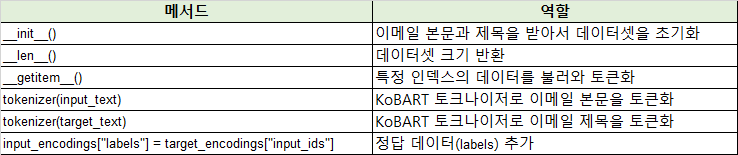
위와 같이 클래스를 만들고 객체를 생성해 줬다. 이 때, 내가 사용한 모델에 맞춰 input length 를 제한하였고 결과로 출력 될 데이터(제목)의 최대 길이는 50자라는 정보를 주었다.
# fast tokenizer의 기본 model_max_length가 매우 클 수 있으므로 안전한 값으로 재설정 (예: 1024)
safe_max_length = 1024
tokenizer.model_max_length = safe_max_length
# 데이터셋 객체 생성
dataset = EmailTitleDataset(
contents=data["content"].tolist(),
titles=data["title"].tolist(),
tokenizer=tokenizer,
max_input_length=safe_max_length,
max_output_length=50
)4. 트레이닝 수행
트레이닝은 transformers 라이브러리의 Traniner, TrainingArguments 클래스를 이용할 것이다.
from transformers import Trainer, TrainingArguments
# 6. TrainingArguments 및 Trainer 설정
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=2,
learning_rate=2e-5,
weight_decay=0.01,
logging_steps=10,
save_total_limit=2,
# 평가 데이터셋이 없는 경우 eval_strategy를 "no"로 설정합니다.
eval_strategy="no"
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset
)
# Fine-tuning 진행 (학습 시작)
trainer.train()5. 트레이닝 결과 저장(선택)
매번 코드 실행 때 마다 모델을 부르고 학습을 할 수도 있지만 모델과 토크나이저를 별도로 저장해 둔 후 이후 꺼내서 사용할 수 있다.
# 학습이 끝난 후 모델과 토크나이저 저장
model.save_pretrained("./fine_tuned_model")
tokenizer.save_pretrained("./fine_tuned_model")위와 같이 저장 하였다면 이후 저장 경로를 지정해 모델을 불러와 사용할 수 있다.
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
# 저장된 모델 경로
model_path = "./fine_tuned_model"
# 1️⃣ 저장된 토크나이저 로드
tokenizer = AutoTokenizer.from_pretrained(model_path)
# 2️⃣ 저장된 모델 로드
model = AutoModelForSeq2SeqLM.from_pretrained(model_path)
print("모델 및 토크나이저 로드 완료")
 에서 개발 시작하기")

