콘텐츠
퍼펫티어(Puppeteer) 는 구글에서 만든 웹 사이트를 컨트롤 하고 정보를 가져올 수 있게 해주는 자동화 라이브러리 입니다.
Node.js 기반으로 자바스크립트를 사용할 줄 안다면 손쉽게 다룰 수 있음에도 기능이 매우 강력해 자동화 프로그램을 만들 때 적극 추천할 수 있습니다.
비공식 래퍼로 자바, 파이썬, C# 에서도 사용이 가능한데요~ 저는 공식적으로 제공되는 Node.js 버전을 가지고 여러가지 프로그램을 개발하는데 빠져들고 있습니다.
Puppeteer 를 사용하기 위해선 사용자 PC 에 Node.js 와 Chromium 기반 웹 브라우저 두 가지가 필요 합니다. 물론 Node.js 를 작성하기 위한 에디터, IDE는 필요하죠. 저는 VSCode 를 사용해 Node.js 애플리케이션을 개발하고 있습니다.
최초로 라이브러리를 install 한 PC 에선 내장 Chromium 브라우저도 설치 되어 사용이 되었고 그 외 Git 을 통해 공유하는 다른 환경에선 브라우저 경로를 옵션으로 지정할 수 있어 협업도 손쉽게 가능 했습니다.
Puppeteer 기본 사용 방법
Puppeteer 기본 사용 방법은 제 블로그 내 Node.js 라이브러리 Puppeteer: 웹 브라우저 자동화 시작하기 게시물로 정리해 두었습니다.
Node.js 가 설치된 환경에서 npm install puppeteer 명령어로 설치 후 바로 사용이 가능합니다.
Puppeteer vs 타 웹 스크래핑 라이브러리
먼저 웹 스크래핑을 구현 하기 전, Puppeteer 와 다른 웹 스크래핑 라이브러리를 비교해서 장단점을 알아 보도록 하겠습니다.
Puppeteer
Puppeteer 는 Node.js 로 되어 있어 다양하고 강력한 Node.js 모듈과 호환 된다는 점, 대부분 파이썬 기반인 다른 라이브러리와 달리 웹 기술인 자바스크립트를 사용하여 애플리케이션 개발이 가능하다는 큰 장점이 있습니다.
그리고 스크래핑 뿐 아닌, 웹 브라우저 자동화 라이브러리 이므로 웹 사이트를 컨트롤 할 수 있어 사이트에 작성되지 않은 HTML, 자바스크립트 코드 등도 작성해 활용이 가능합니다.
그 외에도 헤드리스(백그라운드 모드), 웹 사이트를 PDF 화 등 다양하고 강력한 기능을 제공 합니다.
BeautifulSoup
파이썬 기반의 HTML, XML 파일을 파싱 하는데 사용되는 라이브러리 입니다. Puppeteer 와 같이 웹 페이지의 데이터를 손쉽게 가져오고 조작할 수 있다는 장점이 있습니다.
단, 두 라이브러리 간의 가장 큰 차이점이 있는데 BeautifulSoup 는 동적 컨텐츠인 즉 자바스크립트를 처리하지 못합니다.
그리고 조작 등의 기능도 한정적 이여서 조작과 스크래핑 모두 강력한 Puppeteer 와 달리 Selenium 과 함께 사용되곤 합니다.
Scrapy
Scrapy 또한 파이썬 기반의 웹 크롤링 라이브러리 입니다. 특징으로 Scrapy 에서 크롤링한 데이터를 처리하고 저장하는 내장 되어 있는 데이터 파이프라인, 동일한 URL 의 크롤링을 막는 중복 방지 기능이 있습니다.
크롤링에 대한 라이브러리 이므로 데이터를 수집하는 행위는 같지만 스크래핑에 비해 검색엔진 등, 사이트 내의 정보들을 찾아가며 수집하는데 특화 되어 있습니다.
Scrapy 또한 BeautifulSoup 와 같이 동적 콘텐츠 처리에는 부적합 하단 단점이 있습니다.
Selenium
제가 Puppeteer 를 사용하기 전 고려한 라이브러리 입니다. BeautifulSoup 와 Scrapy 가 웹 스크래핑, 크롤링 등 데이터 수집에 최적화 된 라이브러리 라면 Selenium 은 Puppeteer 와 같이 브라우저 자동화를 위한 프레임워크 입니다.
Puppeteer 이전 부터 유명해 여러 기업에서도 자동화 과제 시 사용하고 있으며 Puppeteer 와 달리 여러 브라우저(Chrome, Firefox, Safari 등) 를 지원 한다는 장점이 있어 웹 테스트에도 강력하게 사용가능합니다.
단점은 강력한 기능이 많은 만큼 성능이 다소 무거운 편이며 처음 설정과 유지 보수가 어려운 부분이 있습니다.
Playwright – ⭐
Puppeteer 는 2017 에 등장한 구글이 제작한 라이브러리 입니다. Playwright 는 그 이후 2020년에 등장하였으며 마이크로소프트가 개발하였고 Selenium 와 같이 여러 브라우저를 지원한다는 장점이 있습니다.
그리고 비공식 래퍼로 커뮤니티에서 다양한 언어에 호환되는 Puppeteer 와 달리 Playwright 는 공식적으로 여러 언어를 지원하고 있습니다.
따라서, 제대로 된 자동화 프로그램을 개발하기 위해 배우겠다 하면 한번 Puppeteer 말고 더 강력한 이 라이브러리를 배워보는 것도 추천 드립니다. 무조건 최신 기술이 좋은 것은 아니지만 공식적으로 여러 언어, 브라우저를 지원 한다는 점은 확실히 매력적인 요소 입니다.
그나마 비교 시 단점을 하나 꼽자면 최신 라이브러리 이므로 커뮤니티 생태계가 다른 라이브러리들에 비해 작다는 점이 있겠네요.
이처럼 여러 라이브러리와 비교해 봤을 때도 Puppeteer 는 강력하며 장점이 많은 라이브러리임을 알 수 있었습니다.
무엇보다 정적 페이지가 아닌 SPA(Single Page Application, 페이지 이동 없이 하나의 페이지에서 동적으로 컨텐츠가 보여지는 웹) 방식의 최신 웹 트렌드에서 사용하기에 적합합니다.
Puppeteer 로 Google 검색 결과 스크래핑 하기
자, 이제 실제로 Puppeteer 로 Google 검색 결과를 스크래핑 해보겠습니다. 먼저 다음과 같은 코드를 작성 하여 브라우저에서 구글로 접속하는 코드를 작성해 봅시다. (자세한 내용이 궁금하다면 이전 게시글을 참고해 주세요.)
const puppeteer = require('puppeteer');
async function run() {
// Puppeteer 인스턴스를 실행
const browser = await puppeteer.launch({
headless: false, //headless 모드를 비활성화 해야 브라우저가 눈에 보입니다.
executablePath: 'C:\\Program Files\\Google\\Chrome\\Application\\chrome.exe' //자신의 PC에 Chrome 경로로 변경해 주세요.
});
const page = await browser.newPage(); //새 탭을 생성후 객체 반환
// Google 웹 페이지를 열기
await page.goto('https://google.com');
}
run();이 코드를 실행하게 되면 크롬 브라우저가 자동으로 열리고 구글 사이트에 접속 되어야 합니다.
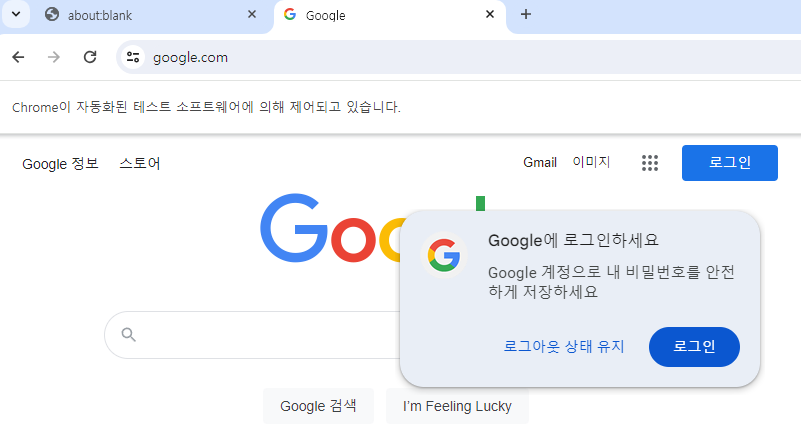
구글 검색 기능 구현하기
이번엔 위의 소스에서 구글 검색 기능을 구현해 보겠습니다. 먼저 Puppeteer 페이지 객체 내용이 담긴 page 변수에서 .evaluate() 메서드를 이용하면 접속한 사이트를 바닐라 자바스크립트를 통해 다룰 수 있습니다. 해당 메서드 안에선 Node.js 의 백엔드 영역이 아닌 프론트엔드 영역의 자바스크립트가 작성됩니다.
다음 코드는 접속한 구글 페이지의 검색 상자를 document.getElementById 를 통해 DOM 객체로 가져온 후 값을 입력해 보겠습니다. 먼저 구글 사이트에서 F12를 입력해 출력 되는 개발자 도구를 통해 검색 상자 요소를 확인해 봅시다.
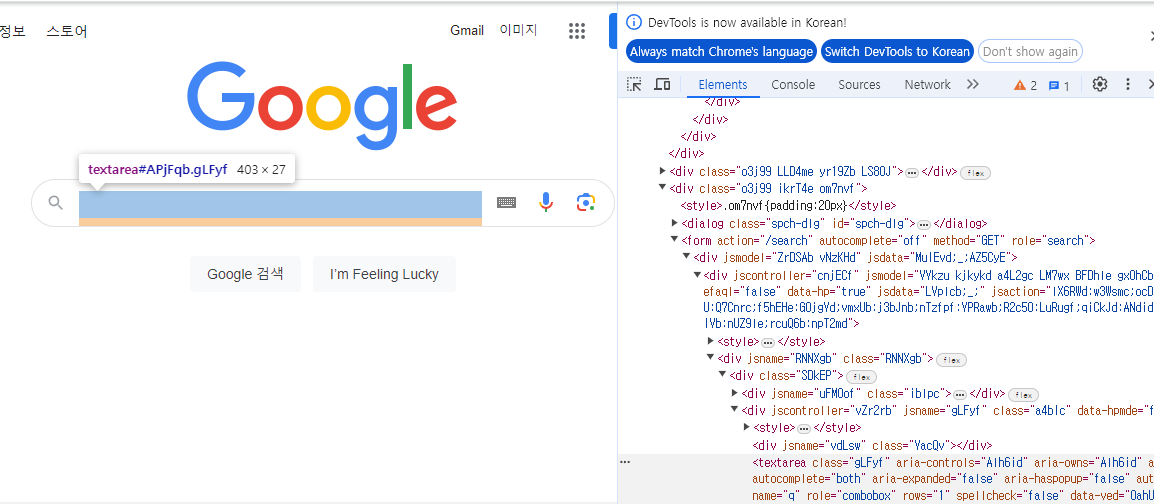
검색 상자를 찾아보니 태그에 ID 속성에 ‘APjFqb’ 란 값이 부여되어 있네요. 그럼 Puppeteer 를 통해 해당 객체를 가져오고 value (검색어)로 ‘2024년 5월 개봉영화’ 를 부여해 보겠습니다.
const puppeteer = require('puppeteer');
async function run() {
// Puppeteer 인스턴스를 실행
const browser = await puppeteer.launch({
headless: false, //headless 모드를 비활성화 해야 브라우저가 눈에 보입니다.
executablePath: 'C:\\Program Files\\Google\\Chrome\\Application\\chrome.exe' //자신의 PC에 Chrome 경로로 변경해 주세요.
});
const page = await browser.newPage(); //새 탭을 생성후 객체 반환
// Google 웹 페이지를 열기
await page.goto('https://google.com');
await page.evaluate(() => {
document.getElementById('APjFqb').value = '2024년 5월 개봉영화';
})
}
run();다시 코드를 실행해 보니 검색 상자에 정상적으로 검색어가 입력되어 있습니다.
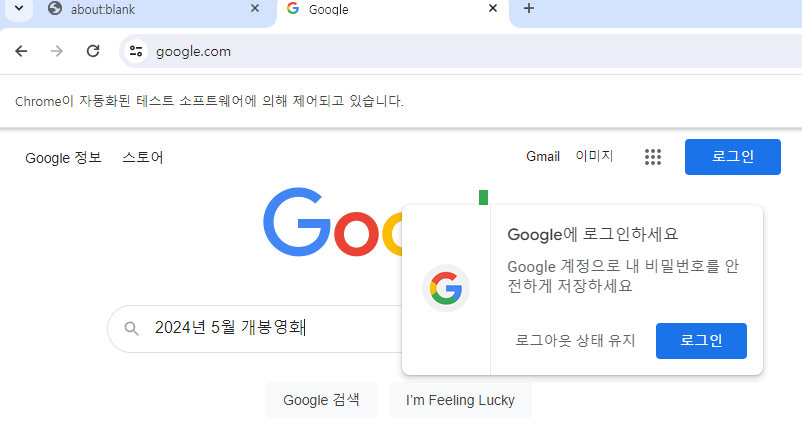
이제 검색어가 입력되어 있으니 ‘엔터’ 키프레스를 발생 시켜 검색이 수행되도록 하겠습니다. evaluate() 메서드 영역에서 디스패치를 이용해 엔터 키 이벤트를 수행할 수도 있지만, Puppeteer 의 메서드를 이용해 엔터 키프레스를 발생시켜 보겠습니다.
방법은 아주 간단한데 다음 코드로 ‘await page.keyboard.press(‘Enter’);’ 코드를 작성해 주면 됩니다.
const puppeteer = require('puppeteer');
async function run() {
// Puppeteer 인스턴스를 실행
const browser = await puppeteer.launch({
headless: false, //headless 모드를 비활성화 해야 브라우저가 눈에 보입니다.
executablePath: 'C:\\Program Files\\Google\\Chrome\\Application\\chrome.exe' //자신의 PC에 Chrome 경로로 변경해 주세요.
});
const page = await browser.newPage(); //새 탭을 생성후 객체 반환
// Google 웹 페이지를 열기
await page.goto('https://google.com');
await page.evaluate(() => {
document.getElementById('APjFqb').value = '2024년 5월 개봉영화';
})
await page.keyboard.press('Enter');
}
run();코드를 실행해 보니 검색이 수행되는 모습을 확인할 수 있었습니다. 👍
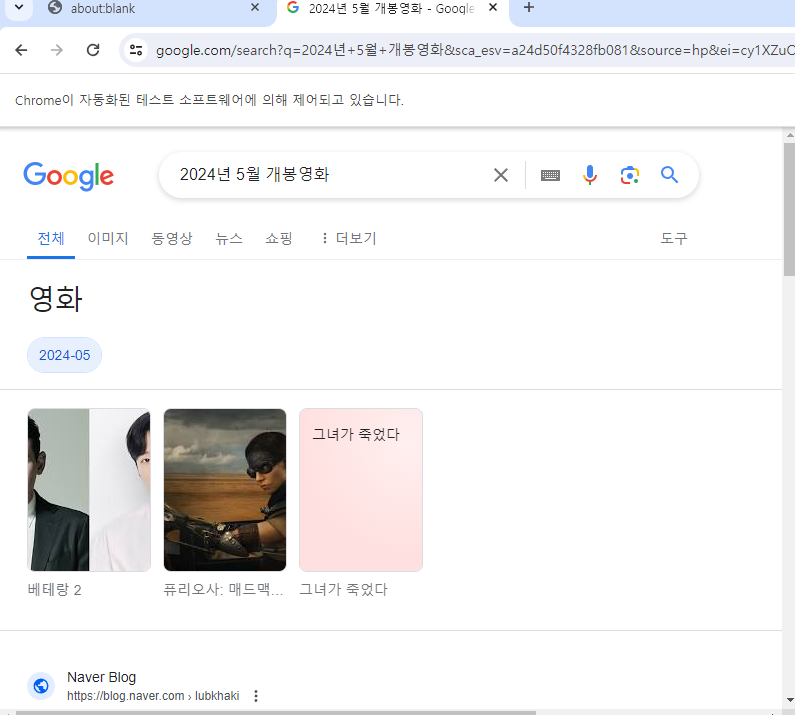
검색 결과 수집하기
이제 한번 검색 결과를 수집해 보겠습니다. 여러 방법을 이용할 수 있지만 위에 이미 사용해 봤던 .evaluate() 메서드를 활용해 보겠습니다.
해당 메서드 안에 return 코드를 작성해 주면 해당 내용이 Node.js 영역의 변수에 담을 수 있어요. 그래서 검색 결과 페이지 내의 제목들을 수집한 후 이를 배열(Array) 변수에 담아 반환해 보겠습니다.
F12 를 통해 확인해 보니 제목들은 h3 태그로 작성되어 있습니다. h3 태그를 수집하고 반환해 보겠습니다. 그 전에 검색 결과가 모두 가져와 출력 되기 전에 코드가 수행 되면 에러가 발생하게 됩니다. 그래서 검색이 완료 되었는지 확인하는 코드를 작성해야 합니다.
제가 검색 완료 확인에 활용한 방법은 Puppeteer 의 waitForSelector() 입니다. 해당 메서드는 CSS 선택자를 이용해 해당 요소가 페이지 내에 나타나기 까지 대기, 반환하는 메서드 입니다.
const puppeteer = require('puppeteer');
async function run() {
// Puppeteer 인스턴스를 실행
const browser = await puppeteer.launch({
headless: false, //headless 모드를 비활성화 해야 브라우저가 눈에 보입니다.
executablePath: 'C:\\Program Files\\Google\\Chrome\\Application\\chrome.exe' //자신의 PC에 Chrome 경로로 변경해 주세요.
});
const page = await browser.newPage(); //새 탭을 생성후 객체 반환
// Google 웹 페이지를 열기
await page.goto('https://google.com');
await page.evaluate(() => {
document.getElementById('APjFqb').value = '2024년 5월 개봉영화';
})
await page.keyboard.press('Enter');
await page.waitForSelector('h3'); // h3 태그가 나타날 때 까지 대기
// h3 태그 내 제목을 가져와 반환 하기
const titleList = await page.evaluate(() => {
const titleList = [];
document.querySelectorAll('h3')?.forEach(el => {
titleList.push(el.textContent);
});
return titleList;
})
// 반환 결과 확인
console.log(titleList);
}
run();위의 태그를 실행해 보니 다음과 같이 결과가 출력 되었습니다.
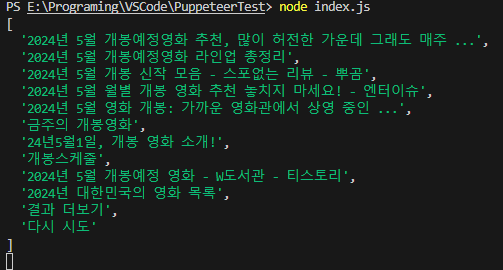
위의 방법을 이용하면 구글 말고도 접근이 가능한 여러 사이트의 정보를 손쉽게 수집할 수 있습니다!! 그런데 구글의 검색 결과는 스크롤에 따라 정보가 더 출력 되는 구조다 보니 아래로 스크롤을 하며 나머지 정보를 수집해야 할 것 같습니다.
혹여 결과 더보기를 눌러 모든 검색 결과를 수집하는 코드가 필요하시다면 댓글 달아주세요. 추가로 포스팅 작성 하겠습니다.
오늘은 Puppeteer 로 간단하게 구글 검색 결과를 스크래핑 해보았습니다. 블로그 글 봐주셔서 감사드립니다.



 서버 내 파일 생성, 삭제, 읽기, 쓰기")